Whenever there’s a revolution in computing, there’s a period of wild experimentation. Ideas are explored, prototypes are built, and manifestos are written.
The final outcome does not always achieve the great ambition of the first prototypes. Not everything works well in practice. Some features prove difficult to build, are punted to v2, and never get shipped.
The World Wide Web, with its HyperText Markup Language, was heavily influenced by the ideas of hypermedia. The idea of hyperlinks — cross-referencing documents — was radical. There were even court cases disputing the right to link to content.
The original concept of hypertext was much more ambitious. Early designs, such as the memex and Project Xanadu, had a richer feature set.
Here’s the web they envisaged.
Back links
Today’s hyperlinks are one-way: when you visit a webpage, you do not know what links point to it. You can only see what links start from it.
It’s useful information, enabling the reader to discover related pages. Indeed, the basic principle of Google’s PageRank is founded on crawling the web to find back links.
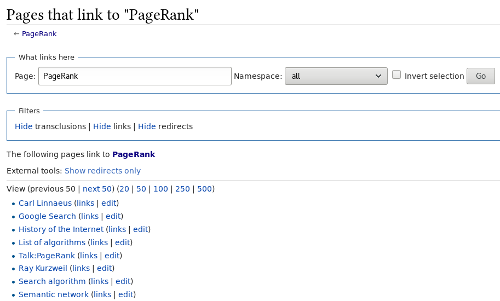
Bidirectional links are alive and well in Wikipedia, which provides a ‘What links here’ feature to discover related topics.
Transclusion
Today’s web cannot include one page in another. You could manually scrape the HTML and paste it in, but then you miss out any future updates.
HTML does provide the <iframe> tag, but the embedded content does
not flow into the original page. It’s clunky and rarely used in
practice.
Twitter, with its many constraints, does provide a transclusion facility.
Blogged: Effortless Major Mode Development https://t.co/e7Wm4Im0SL #emacs
— Wilfred Hughes (@_wilfredh) April 28, 2016
The above embedded tweet contains the current retweet and like counts, without me updating my blog post.
Twitter takes this idea further in its clients. If a tweet contains a hyperlink, it includes a preview – another form of transclusion!
Twitter calls this functionality Twitter Cards. For short content, such as other tweets, the preview includes the entire content.
Unique IDs
Web pages are identified by URLs, which are usually unique. Despite W3C pleas not to break URLs, link rot is a very common problem.
Link rot can prevented by adding another level of indirection. PURLs (Persistent URLs) allow users to refer to an URL which they can update if the underlying URL changes.
For example, Keith Shafer (one of the original PURL developers), has a personal web page at purl.oclc.org/keith/home. This originally linked to www.oclc.org:5046/~shafer, which no longer resolves. However, the PURL has been updated, so visitors are now redirected to docs.google.com/document/d/1tnDck…/.
A common source of link rot is page renaming. Stack Overflow, a Q&A site, includes question titles in URLs. These are often edited to clarify the question. Stack Overflow embeds unique question IDs in its URLs to ensure old links work.
Thus http://stackoverflow.com/questions/37089768/does-pharo-provide-tail-call-optimisation is the canonical URL, but http://stackoverflow.com/questions/37089768/foobar still works.
Section links
URLs in today’s web can also reference named HTML tags. For example, http://wilfred.me.uk/blog/2016/06/12/hypermedia-how-the-www-fell-short/#unique-ids directly links to this section of this blog post. However, this requires co-operation from the author: they must provide named anchors, which cannot change in future.
A common UI pattern is provide discoverable links on headings in web pages. This assumes that headings never change or repeat in a document, but fits the common use case.
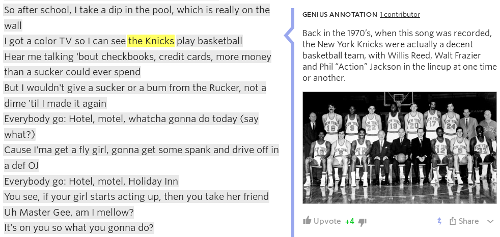
The other major limitation of section links is that they cannot reference a range of tags on a page. Genius (a website offering song lyric interpretations) is one of very few websites that allow users to link to arbitrary sections of a page.
History
Finally, early hypermedia designs kept historical versions of content. You could link to old versions of content if desired.
We don’t have this in today’s web. There’s the Wayback Machine, which periodically snapshots many websites. For high-profile online news, NewsDiffs regularly snapshots stories to see how articles are edited over time.
This is another example where wikis come closer to the traditional idea of hypermedia. https://en.wikipedia.org/wiki/Hypertext links to the current version of the hypertext article on Wikipedia, whereas https://en.wikipedia.org/w/index.php?title=Hypertext&oldid=722248276 explicitly links to the version at time of writing, regardless of future changes.
Looking Forward
Should we throw away today’s web and rebuild? Certainly not.
The web we have works incredibly well. Its feature set has enabled users to write billions of web pages. The technology is standardised and there are many mature implementations.
HTML is still a medium where some things are easy and some things are not. We should not lose sight of how HTML will affect how we communicate. Instead, we should pillage the ideas of the past to make the best use of our content today.