Esperanta traduko venos / Esperanto translation will be added.
There are several online Esperanto dictionaries out there, as well as freely available definition collections for those who wish to build their own Esperanto dictionary applications. I was unhappy with the inflexibility of existing online dictionaries, so I decided to build my own.
Goals
My primary goal was to create an Esperanto dictionary website that was attractive, easy to use and allowed the user to search for words as they occur in practice, in the real world. Specifically, this meant my dictionary should allow the user to search for:
- words with any ending (nouns may have plural or accusative endings, verbs may be in any tense)
- words in any writing system (Esperanto has three different writing systems that are frequently used)
- words with misspellings
- novel compound words (the morphology of Esperanto is very agglutinative and novel combinations are fairly common)
Existing solutions
The most well used online Esperanto dictionary today is probably ReVo. ReVo already has an online search facility, but offered none of the flexibility I was seeking. Its interface is based on HTML frames (making it impossible to link directly to specific pages) and the URL is not easily memorable (their preferred form is http://purl.org/net/voko/revo). I also found the search tool frustrating as it immediately offered the English translation before the reader had a chance to see the Esperanto definition, limiting its usefulness as a way of practising.
The other well-used Esperanto dictionary is that on Lernu, which is primarily intended for learners. This dictionary only includes short definitions but they are available in many languages. It is substantially more flexible, supporting two of the three writing systems and allowing different endings. It also has limited support for compound words, but careful examination showed that this is only a list of common compounds rather than a general tool (an interested reader can compare plibonigi (to improve) with plidolĉigi (to sweeten) in the Lernu dictionary; only the first one works).
I also spent some time examining vlasisku, an online dictionary for users of Lojban (another artificial language but one that is far more easily manipulable by computers). Vlasisku (the name itself is a Lojban compound meaning word searcher) supports compound words and offers a simple interface and so was a major influence on my early designs.
Implementation
After considering the limitations of these other dictionaries, my target feature set became:
- A simple and intuitive interface, allowing content to be found easily and avoiding the use of acronyms
- A large collection of definitions to maximise the site’s usefulness
- The ability to search for words as they are written in the wild
Interface
Originally I considered a minimalist interface with a focus on typography, influenced by the interface of vlasisku. I experimented with web font embedding to achieve an ‘expensive restaurant menu’ look. However my last web project used minimalism in part as a way of avoiding thinking about graphical design. I wanted to avoid that. I also came across thesixtyone, a music site that used imagery of the artists for the page background. I settled on this approach as I prototyped and learnt the gory details of CSS.
![]()
An early logo design, focusing more on typography for the restaurant menu concept

A prototype influenced by thesixtyone, even down to text position
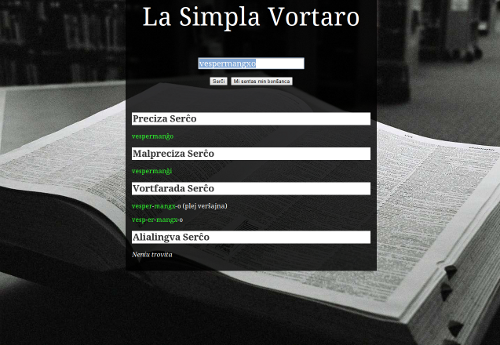
The final design of the interface, using centred divs so the page can grow vertically
Choosing a domain name was another early decision I had to make. Having already chosen my license (AGPLv3) and code hosting service (GitHub), my project name would be public during development. To avoid someone else registering it before me, I needed to register the domain at the outset.
Romania has the domain TLD .ro and I considered using the word Vortaro (the Esperanto word for dictionary) as a domain hack. This was famously done by the bookmarking site del.icio.us but I was concerned that users would find vorta.ro difficult to remember. Delicious was later forced to buy delicious.com to make the site more accessible.
To make the domain simple and memorable I settled on the name La Simpla Vortaro (The Simple Dictionary) with the domain simplavortaro.org.
Word Definitions
Obtaining definitions proved to be quite a challenge. Whilst there are several freely available collections of definitions, the most comprehensive collection is produced by ReVo. Word definitions in ReVo include examples, usage remarks and translations rather than just a short definition.
ReVo is based on a public domain dictionary La Plena Vortaro de Esperanto that was released in 1930 and updated in 1934. Today the definitions can be updated by anyone by editing the XML and consists of almost 24,000 words. However, this handwritten XML has a deeply complex structure and incomplete documentation. Extracting the data into a format suitable for working with consumed a substantial proportion of the total development time.
Ultimately, my solution was to build an XML to JSON converter. Due to the complexity of this tool I split this out into a separate GitHub project. My converter tool is lossy as a result of the astonishing flexibility of the XML format used. One good example of this is the facility for dictionary definition editors to add remarks. These may be added to words, definitions, subdefinitions, examples or subwords. For the sake of presenting a simple interface to the user and having a sane database structure I made the decision to only allow remarks on definitions.
My approach for data extraction is an XML tree walker (using the lxml Python library) that flattens tree branches whilst allowing specifc subtrees to be excluded. My initial approach was more complex but it gradually became clear that most of my methods were some variation upon this theme.
Additionally, with such a complex and varied set of files to extract from it was necessary for me to develop a test suite of unusually complex definition files to ensure data was being extracted correctly.
Search
With a dataset in hand, I could think about search. I prototyped a few simple spell checking algorithms in Python and after success with that I selected the Django web framework to run my site. This enabled me to build out from my prototypes rather than port them to another language.
Search: Spell Check
I first implemented a spell check, since this feature was unavailable on other dictionaries. I started with this article by Peter Norvig and built a simple spell checker that corrects any single error.
Norvig’s solution uses a corpus (i.e. a large collection of text which can be analysed to measure real word usage) in order to present the most likely correct spelling to the user. I decided not to compile a corpus but instead to show every possible word that the user may have intended. On the frontend I describe this as an ‘imprecise search’. An advantage of this approach is that I can always show similarly spelt words, even if the search term is spelt correctly.
As I implemented the spell checker, it allowed a word to be incorrect because of:
- a letter being deleted;
- two adjacent letters being transposed;
- a superfluous letter being inserted; or
- an incorrect letter used in the place of another.
Since the imprecise search only considered lower case and the Esperanto alphabet consists of 28 letters, the final complexity of the spell checker was O(57n+29) (where n is the number of characters in the word). Of course, correcting two errors would be O((57n+29)²) and so on so I decided that one error was sufficient for my purposes.
In practice, I limit the number of possible variations to 999 so that only one database query is made (999 being the limit of my database for a single IN query) so words longer than 17 characters will not have every possible single error checked. To alleviate this I rank the different error types to ensure more likely errors (transpositions being considered the most probable) come earlier and so are less likely to be thrown away when the 999 limit is reached.
Search: Writing Systems
The next step was to support searching in any writing system. There are three major writing systems in Esperanto:
- accented letters (eĥoŝanĝo ĉiuĵaŭde),
- the x-system (ehxosxangxo cxiujxauxde), and
- the h-system (ehhoshangho chiujhaude).
Many sites (most famously the Esperanto language Wikipedia) use the x-system because it is unambiguous and readily typed on most devices. However, allowing the user to search for text from any source meant I had to support all three. The careful reader will notice that the h-system is a lossy conversion (ŭ is mapped to the already used letter u) and so conversion between writing systems is non-trivial. Even recognising which writing system is in use for a search term is not always possible.
My solution here was to simply generate each search term in each writing system in advance. Whilst it would be extremely difficult to programmatically find the accented form of a word from its h-system representation, the conversion is trivial when starting from the accented form, which is the system used in my definition lists.
I therefore generated a list of possible ways of writing each word from the definition lists. This enables the user to search any of (for example) ĉiu, cxiu or chui and still find the correct result. A major advantage of this approach is that I can run the spell checker over this larger list, allowing the dictionary to offer alternatives to obvious errors such as xciu. A naive writing system conversion would not be capable of this.
Search: Word Endings
Always forcing users to search for verbs in their infinitive form or nouns in the singular genitive case is not ideal. In practice, Esperanto word endings show what type of word a given word belongs to, so it is easy even for a beginner to work out kato (singular genitive of cat) from katojn (plural accusative of cat). However, there are a small number of exceptions to this (particularly onomatopoeia), and this was a problem that I had to solve in order to allow words as they occur in the wild to be searched.
As with writing systems, I generated every possible word form from the definition lists. These lists always had nouns in the singular, verbs as infinitives and so on. However, generating every possible conjugation and declension required a programmatic way to determine word types.
This required me to build a simple word classifier. My classifier simply identifies words based on ending, with a blacklist for exceptions. For example, every noun in Esperanto ends with -o and there are only three words that end -o which are not nouns (po, a preposition, do, a conjunction and ho, an exclamation).
Once words were classified I could then generate every possible tense and case. For example, from the word fromaĝo (cheese) I generate:
fromaĝo, fromaĝon, fromaĝoj, fromaĝojn
To conserve writing system flexibility I then generated every possible way of writing those words:
fromaĝo, fromaĝon, fromaĝoj, fromaĝojn, fromagxo, fromagxon, fromagxoj, fromagxojn, fromagho, fromaghon, fromaghoj, fromaghojn
This final list became the list of possibilites for the spell checker.
Compound Word Analysis
In practice, Esperantists will form compound words that cannot be found in a dictionary. This was the most interesting challenge I faced during development.
In Esperanto you can combine affixes and/or words to coin new terms. Only the most common compounds will be added to a dictionary. However, it is a sufficiently regular process that I thought I could make some headway in creating a completely general tool.
As mentioned earlier, I examined vlasisku’s approach for deconstructing Lojban compounds. However, Lojban word roots (“rafsi”) have the ‘prefix property’ of data coding, so Lojban compounds (“lujvo”) are always unambiguous. Esperanto compounds are substantially more complex so I needed another solution.
I also discovered that Esperanto has specialist compound word dictionaries, but these were just simple lists. As far as I am aware, this problem has not been tackled before.
Since compounds Esperanto words can be novel, I could not simply generate possibilities from my definition lists. I therefore needed to break down words and analyse their constituent parts.
For the sake of an example, consider plidolĉigi (to sweeten), which would be written pli-dolĉ-igi in a textbook for beginners.
Stemming
An Esperanto compound word consists of several word roots (or whole words) concatenated together, along with an appropriate word ending. Separating a compound into its constituents therefore consisted of two steps: (1) removing the ending, and (2) separating out the components.
To remove the ending, I needed to build a stemmer. In the case of plidolĉigi I want to separate it into ‘plidolĉ-’, its compound stem and ‘-i’, the ending. There is a wealth of research out there on stemming but Esperanto has so few irregularities that I could simply write a short blacklist for each word ending.
I built the stemmer by extending the word classifier, again using my definition lists as a search aid in order to see what needed to go in the blacklists. The first version of my word classifier only handled word endings used in the dictionary, but it was clear that for stemming arbitrary words I needed to consider every possible ending (e.g. plural endings). This was a simple matter of searching the definition lists with regular expressions to find every exception for every ending.
Compound words can be constructed using any type of word, including words that do not have an ending that shows their their word type (such as prepositions). As a result, my word segmenter will simply attempt to segment the entire word if the word classifier cannot work out the ending.
Word Segmentation
To separate the stem into its constituent components, a little more thought was needed. The ReVo dataset was laid out in such a way that obtaining a list of word roots was relatively easy. For example, ‘dolĉa’ (sweet) is already shown as having the root ‘dolĉ-’.
With a list of word roots in hand, separating the compound stem into word roots was a matter of considering every possible substring and checking each on against the list. Obviously a naïve algorithm would be O(2^n) in the size of the string. However, few substrings are valid word components and there is no point considering the end if there is beginning is not a valid word component. My solution was to work left to right and only consider the remaining characters in the string if all the previous characters were a valid concatenation of word roots.
My final algorithm was as follows:
def find_roots(compound):
"""Given a word that has been put together using Esperanto roots,
find those roots. We do this by working left to right and building
up a list of all possible radikoj according to the substrings seen
so far.
Since we assume roots are intact, the suffices -ĉjo and -njo which
modify the roots cannot be used with this approach.
For a given string, there are 2^(n-1) possible ways to split it
into substrings so this algorithm is still potentially
exponential. However, since we work left to right and don't
examine the remainder if a prefix isn't valid, the performance
isn't much worse than linear.
>>> find_roots('plifortigas')
[['pli', 'fort', 'ig', 'as']]
>>> find_roots('persone')
[['person', 'e'], ['per', 'son', 'e']]
"""
if compound == "":
return [[]]
splits = []
for i in range(1, len(compound) + 1):
match = find_matching(compound[0:i])
if not match is None:
# this seems to be a valid word or root
# so see if the remainder is valid
endings = find_roots(compound[i:])
for ending in endings:
splits.append([match] + ending)
# if there are multiple parses, ensure the first one is the most
# likely possibility
splits.sort(key=score_parse)
return splitsTesting this approach showed that it could parse many common compound words (plidolĉigi is correctly separated into pli-dolĉ-ig-i) but I had assumed that compounds words only consisted of word roots. In practise it is grammatical and fairly common to use whole words as components: whilst bird-kant-o (birdsong) is grammatical, birdo-kant-o is far more common as it easier to say and is considered to sound more attractive.
I solved this problem by adding whole words to my lists of word compounds. However, this introduced additional scope for ambiguity. There were several words whose roots happened to be valid (but different) words in their own right. For example, the word novao (the astronomical term supernova) has the root nova-, but nova (new) is a word in its own right. I concluded that in these cases to simply choose the more frequently used word of the two (so nova in this example) and have so far not found any pathological examples.
Ambiguous Segmentation
The other challenge I faced with word segmentation is that there are sometimes multiple possible parses. Only around 10% of the words I tested produced multiple possibilities, with longer words being more likely. Generally there is one correct answer, but there do exist puns which exploit this ambiguity.
If we consider the word vespermanĝo, there are two possible parses: vesper-manĝ-o and vesp-er-manĝo. The former literally means ‘evening meal’ and the latter would mean ‘wasp-pieces-meal’ – clearly the former is correct. A simple heuristic would be to assume it is always better to have fewer compounds, but this failed on around 25% of ambiguous compound words that I tested. For example, homarano can be parsed as homa-ran-o (human frog) or hom-ar-an-o (member of the human race) but the latter meaning is almost always intended.
To properly solve this problem I needed some sort of scoring algorithm to choose the most likely parse. Initially I considered a genetic algorithm approach to develop a good classifier, so I collected list of ambiguous compound words that I had parsed by hand. Examining my test cases I felt that such a heavyweight approach was unnecessary and with a little trial and error developed the following scoring algorithm:
badness = number of components - 0.5 * number of affixes
Although any word may be used in a compound word, Esperanto also has a group of affixes that may be used to change the compound word’s meaning. These affixes are very flexible and frequently used, so their presence makes a given parse more likely. Common affixes include -ig (similar to ‘-ify’ in English e.g. beligi signifies ‘beautify’) and -in (similar to ‘-ess’ in English e.g. leonino signfies ‘lioness’).
As a result, reducing the badness score for words with affixes enabled my word segmentation tool to pass every example in the test suite, fixing previously problematic words such as mal-ferm-ilo (‘un-close-tool’ i.e. an opener) which was confused with mal-fer-mil-o (‘un-iron-thousand’ which is nonsensical).
Once sorted, the website displayed the two parses with the lowest badness scores. Although my scoring algorithm ensured the word with the lowest badness is a correct parse, there exists a minority of words with two correct parses. For example, persone can mean person-e (personally) or per-son-e (by means of sound). Therefore only showing one result would sometimes be unhelpful. During my testing, I never discovered any compound word which had more than two correct parses so two seemed an acceptable compromise.
Conclusions
The final product was released after three months of development and fulfilled all my initial objectives. I learnt a huge amount about web programming, dipped my toes into natural language processing and pushed the state of the art. Interested users are welcome to contact me, checkout the code or just play with the site. If nothing else, I find it an indispensable tool for my needs.
Every good work of software starts by scratching a developer's personal itch. -- Eric Raymond