Time for another Emacs adventure!
In Emacs today, there’s no way to find all the callers of a function or macro. Most Emacsers just grab their favourite text search tool. Sadly, dumb text search knows nothing of syntax.
We can do better. It just wouldn’t be Emacs without a little fanatical tool building. Let’s make this happen.
Parsing
Everyone know how to parse lisp, right? It’s just read.
It turns out that a homoiconic language is hard to parse when you want to know where you found the code in the first place. In a language with a separate AST, the AST type includes file positions. In lisp, you just have… a list. No frills.
I briefly explored writing my own parser before coming to my senses. Did you know the following is legal elisp?
;; Variables can start with numbers:
(let ((0x0 1))
;; And a backquote does not have to immediately precede the
;; expression it's quoting:
`
;; foo
(+ ,0x0))Cripes.
Anyway, I totally ripped off was inspired by similar functionality
in el-search. read
moves point to the end of the expression read, and you can use
scan-sexps to find the beginning. Using this technique
recursively, you can find the position of every form in a file.
Analysing
OK, we’ve parsed our code, preserving positions. Which forms actually look like function calls?
This requires a little thought. Here are some tricky examples:
;; Not references to `foo' as a function.
(defun some-func (foo))
(lambda (foo))
(let (foo))
(let ((foo)))
;; Calls to `foo'.
(foo)
(lambda (x) (foo))
(let (x) (foo))
(let ((x (foo))) (foo))
(funcall 'foo)
;; Not necessarily a call, but definitely a reference to
;; the function `foo'.
(a-func #'foo)We can’t simply walk the list: (foo) may or may not be a function
call, depending on context. To model context, we build a ‘path’ that
describes the contextual position of the current form.
A path is just a list that shows the first element of all the
enclosing forms, plus our position within it. For example, given the
code (let (x) (bar) (setq x (foo))), we build a path ((setq . 2)
(let . 3)) when looking at the (foo).
This gives us enough context to recognise function calls in normal code. “Aha!”, says the experienced lisper. “What about macros?”
Well, elisp-refs understands a few common macros. Most macros just evaluate most of their arguments. This means we can just walk the form and spot most function calls.
This isn’t perfect, but it works very well in practice. We also
provide an elisp-refs-symbol command that finds all references to a
symbol, regardless of its position in forms.
Performance
It turns out that Emacs has a ton of elisp. My current instance has loaded three quarters of a million lines of code. Emacs actually lazily loads files, so that’s only the functionality that I use!
So, uh, a little optimisation was needed. I wrote a benchmark script and learnt how to make elisp fast.
Firstly, avoid doing work. elisp-refs needs to calculate form positions, so users can jump to the file at the correct location. However, if a form doesn’t contain any matches, we don’t need to do this expensive calculation at all.
Secondly, find shortcuts. Emacs has a little-known variable
called read-with-symbol-positions. This variable reports all the
symbols read when parsing a form. If we’re looking for function calls
to some-func, and there’s no reference to the symbol some-func, we
can skip that form entirely.
Thirdly, use C functions. CS algorithms says that building a hash
map gives you fast lookup. In elisp-refs, we use assoc with small
alists, because C functions are fast and most lists weren’t big enough
to benefit from the O(1) lookup.
Fourthly, write impure functions. Elisp provides various ways to
preserve the state of the current buffer, particularly
save-excursion and with-current-buffer. This bookkeeping is
expensive, so elisp-refs just creates its own temporary buffers and
dirties them.
When all else fails, cheat. elisp-refs reports its progress, which doesn’t make it faster, but it certainly feels like it.
Display
We have something that works, and we can search in all the code in in the current Emacs instance in less than 10 seconds. How do we display results?
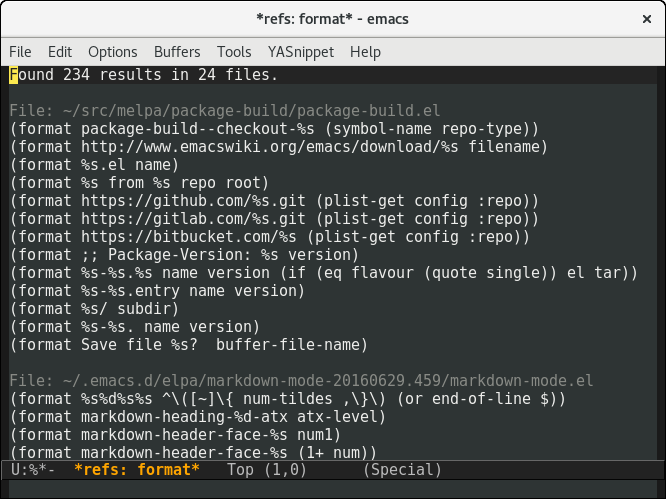
Initially, I just displayed each form in the results buffer. It turns out that the context is useful, so added the rest of the matching lines too. To avoid confusion, I underlined the section of the code that matched the search.
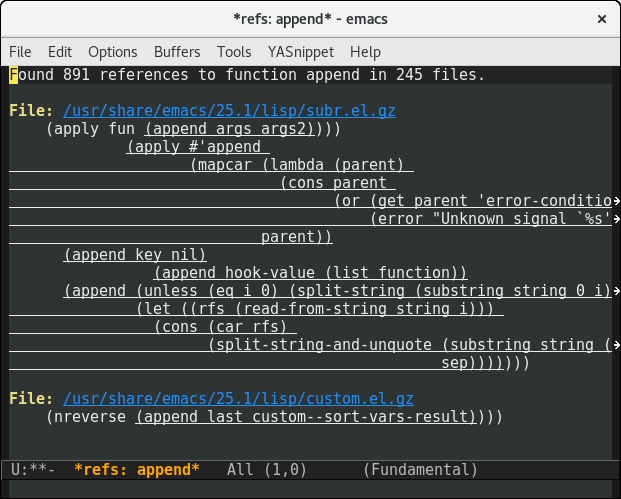
The second prototype also had some custom faces for styling. This was an improvement, but it forces all Emacs theme authors to add support for the faces defined in our package.
It still didn’t work as well as I’d hoped. When I get stuck with UI, I ask ‘what would magit do?’. I decided that magit would take advantage of existing Emacs faces.
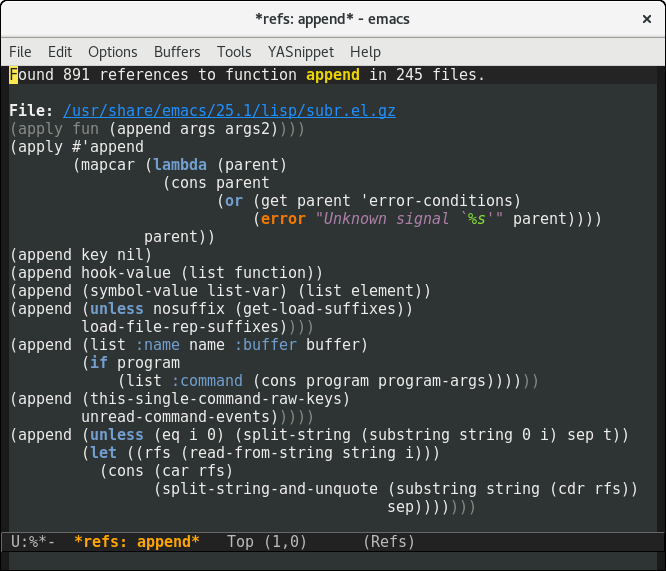
The final version uses standard elisp highlighting, but highlights the surrounding context as comments. This means it will match your favourite colour scheme, and new users should find the UI familiar.
I added a few other flourishes too. You can see that results in the second prototype were often very indented. The final version unindents each result, to make the matches easier to read quickly.
Wrap-Up
elisp-refs is available on GitHub, available on MELPA, and it’s ready for your use! Go forth, and search your elisp!